목차
- numpy
- pandas
- visualization
- 분석 예제
이번 글에선 파이썬 데이터 분석에 쓰이는 라이브러리 (numpy, pandas, matplotlib)의 사용법을 알아보겠습니다.
그 뒤 실제 데이터에 라이브러리를 써서, 간단히 분석을 해볼께요.
0. dimension (차원)
리스트를 쓰다보면 중첩된 구조를 쓰는 경우가 종종 있습니다.
중첩되었다는 건, 리스트 안에 리스트가 있는 건데요.
데이터 쪽에서는 중첩된 정도를 구분하기 위해 차원이란 말을 씁니다.
1번 중첩되면 1차원, 2번 중첩되면 2차원이죠.
xxxxxxxxxx[1,2,3,4] # 1차원[[10,11,12], [30, 40, 50]] # 2차원[ [[100,110,120], [130, 140, 150]], [[200,210,220], [230, 240, 250]]] # 3차원일반적인 리스트로는 중첩된 자료를 처리하는 게 느리고, 복잡해서 numpy(넘파이)라는 라이브러리를 많이 씁니다.
1. numpy (넘파이)
numpy는 과학 연산을 위한 라이브러리입니다. 리스트, 배열, 매트릭스 연산을 빠르게 하는 걸 도와줍니다.
리스트와 넘파이의 속도 차이는 30~40배까지도 난다고 하네요.
데이터가 커질수록 넘파이는 필수겠죠.
numpy의 배열(array)를 쓰는 법을 알아볼께요.
xxxxxxxxxximport numpy as npa = np.array([1,2,3])# 1행print(a.shape)print(a[0])print(a[1])b = np.array( [[1,2,3], [4,5,6]])# 2행 3열print(b.shape)print(b[0])print(b[1])print(b[0, 1])print(b[1, 1])c = [[1,2,3], [4,5,6]]print(c[0][1]) 넘파이도 리스트처럼, 인덱스로 원하는 값을 접근할 수 있습니다. 다만 2차원 넘파이부터는 데이터 접근 방식이 좀 다릅니다.
xxxxxxxxxximport numpy as npa = np.array([ [1,2], [3,4], [5,6]])# 조건을 적용할 수 있다. bool_idx = (a > 2 )print(bool_idx)# 2보다 큰 값만 출력한다.print(a[ a > 2 ])xxxxxxxxxximport numpy as npa = np.array([ [1,2], [3,4]])b = np.array([ [10, 11], [12, 13]])print(a + b)print(np.add(a, b))print(a - b)print(np.subtract(a, b))print(a * b)print(np.multiply(a, b))print(a / b)print(np.multiply(a, b))xxxxxxxxxximport numpy as npx = np.array([ [1,2,3], [4,5,6] ])print(np.sum(x, axis=0)) # 열(column)끼리 값을 더합니다. print(np.sum(x, axis=1)) # 행(row)끼리 값을 더합니다.2. pandas (판다스)
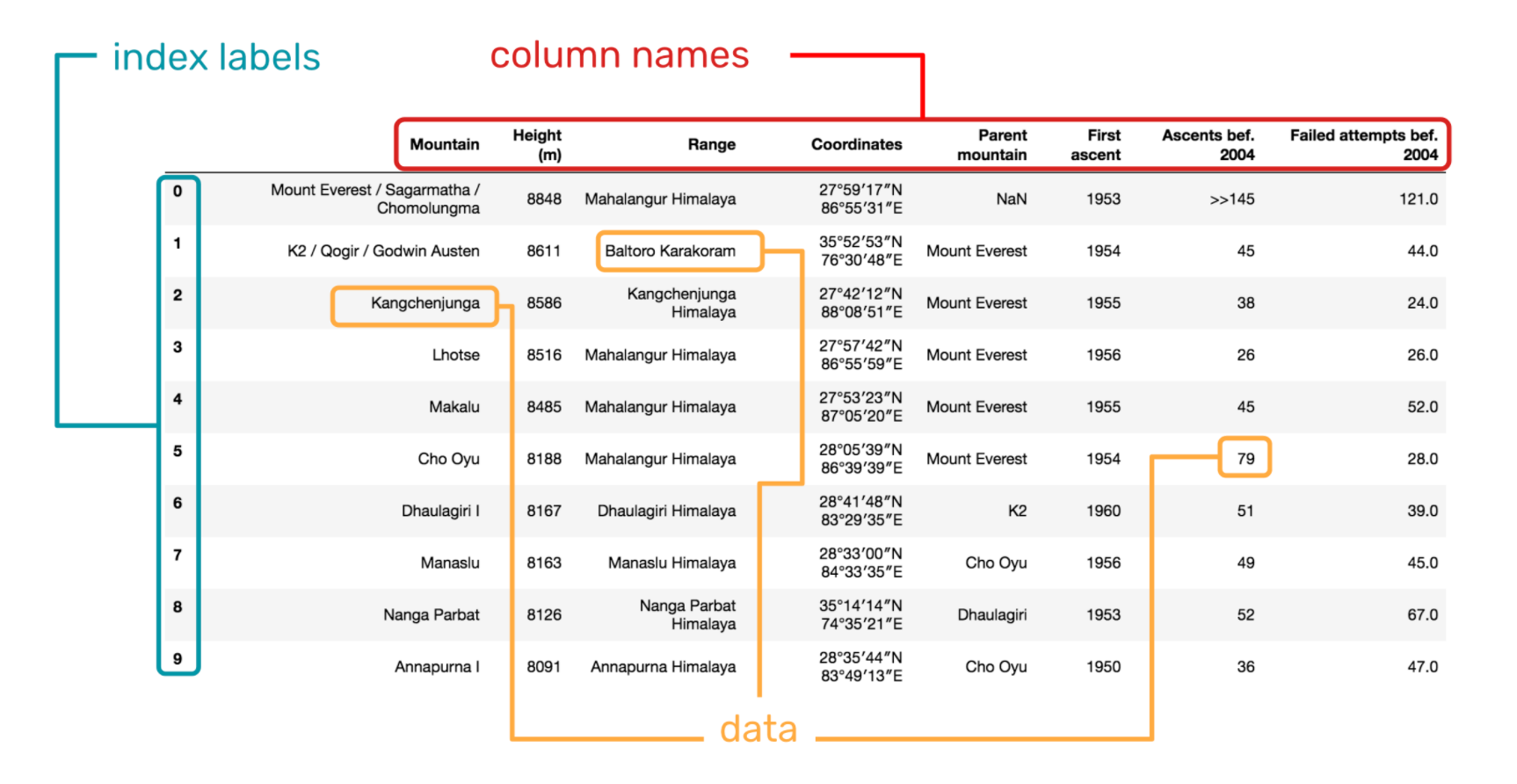
2.1 pandas - 열과 행 다뤄보기
데이터 프레임은 행과 열로 이루어진 표입니다. 데이터 프레임을 이용하면 각 열(칼럼)에 있는 값을 편하게 쓸 수 있습니다. 평균 나이를 구하거나, 성적이 상위 20%인 사람을 구하는 것도 쉽죠.
데이터 프레임은 행과 열로 데이터를 구분합니다.
행을 index(인덱스)리고 부르고, 열은 칼럼이라고 부르죠.
xxxxxxxxxximport pandas as pd# 딕셔너리의 키를 열이름(칼럼명)으로 쓴다. df = pd.DataFrame({ 'name': ['Bob', 'Alice', 'Jane'], 'age': [71, 33, 58]})print(df)# (3,2) 출력. 3행 2열의 데이터 프레임이란 뜻이다.print(df.shape) # 열 별로 데이터를 이용할 수 있다.print(df['age']) print(df['name'])print(df[:1])print(df.index) # 인덱스 알아보기. print(df.columns) # 칼럼 알아보기.
2.2 pandas - 필터링 및 정렬 하기
데이터 프레임의 기본 기능을 사용하면 원하는 데이터만 쉽게 필터링 하고, 정렬할 수 있죠!
보통 엑셀을 많이 쓰는 이유가 정렬이나 필터링, vlookup 같은 기능 때문인데요.
파이썬을 쓰면 엑셀의 모든 기능을 쉽게 대체할 수 있습니다.
물론 속도는 파이썬이 비교할 수 없을 정도로 빠르구요.
xxxxxxxxxximport pandas as pddf = pd.DataFrame({ 'weight': [91, 85, 100, 75, 43, 38], 'height': [180, 173, 190, 170, 163, 152], 'gender': ['male','female', 'male', 'female', 'female', 'male']})print(df['weight'] > 80) # weight가 80 이상이면 True 아니면 False인 데이터 프레임을 만듬.df_filtered = df[df['weight'] > 80]print(df_filtered) # weight가 80 이상인 값만 남았습니다.df_sorted = df_filtered.sort_values('weight', ascending=True) # weight 기준으로 오름차순으로 정렬. 몸무게가 적은 순으로 정렬print(df_sorted)df_sorted = df_filtered.sort_values('height', ascending=False) # height 기준으로 내림차순으로 정렬. 키가 큰 순으로 정렬.df_grouped = df.groupby('gender') # 데이터를 그룹으로 묶어줍니다. 성별에 따라 키와 몸무게를 그룹으로 만들겠죠.df_grouped_mean = df_grouped.mean() # 성별에 따른 키와 몸무게의 평균for key, group in df_grouped: print(key) # 그룹을 묶을 때 쓴 키입니다. print(group) # 키로 묶인 그룹입니다.
2.3 pandas - 통계 관련 함수
판다스는 다양한 내장 함수를 제공합니다.
기초적인 통계를 구할 때 유용하죠.
총합(sum), 평균(mean), 상관관계(correlation), 누적합(cursum), 요약(describe) 등 지원하는 함수가 많습니다.
xxxxxxxxxximport pandas as pddf = pd.DataFrame({ '몸무게': [70, 80, 90, 82, 91], '키': [170, 181, 185, 168, 180]})total_age = df['몸무게'].sum() # 몸무게 총합을 구한다.print(total_age)mean_age = df['키'].mean() # 키의 평균을 구한다.print(mean_age)print(df.describe()) # 요약된 통계 결과를 보여줍니다.corr = df.corr() # 항목들간의 상관관계를 보여줍니다.print(corr) # 상관 계수가 1에 가까울 수록 양의 상관관계가 있고, -1에 가까울수록 음의 상관관계가 있고, 0에 가까울수록 서로 상관이 없습니다.(독립적)
2.4 pandas - csv 읽기와 저장하기
csv 읽고 쓰는 건 정말 간단합니다.
xxxxxxxxxximport pandas as pddf = pd.read_csv('my_csv.csv') # 읽기print(df)한줄이면 쓰기가 됩니다.
xxxxxxxxxximport pandas as pddf = pd.DataFrame({ 'name': ['Bob', 'Jane', 'Mike'], 'age': [20, 33, 45]})df.to_csv('my_data.csv') # 쓰기3. matplotlib - 시각화 라이브러리
매트플롯은 데이터를 시각화 할 때 쓰는 라이브러리입니다.
곡선이나 원, 막대 그래프 등을 그릴 수 있죠.
간단한 그래프 그려보기
xxxxxxxxxximport matplotlib.pyplot as pltx = [1, 2, 3]y = [0, 1, 2]plt.plot(x, y) # 그래프 그리기plt.show() # 그래프 보여주기사인 곡선 그려보기
xxxxxxxxxximport numpy as npimport matplotlib.pyplot as pltx = np.arange(0, 10, 0.1) # np.arange()는 리스트를 만들 때 씁니다. np.arange(시작점,끝점,증가량)이죠.print(x) y = np.sin(x)plt.plot(x, y)plt.show()
여러 그래프 같이 그려보기
xxxxxxxxxximport numpy as npimport matplotlib.pyplot as pltt = np.arange(0., 10., 0.2)# 여러 점 동시에 그리기. plt.plot(t, t, 'r--', # x축 값은 t, y축 값은 y t, 2 * t, 'bs', # x축 값은 t, y축 값은 2 *t t, t**2, 'g^') # x 축 값은 t, y 축 값은 t^2plt.title('several graphs') # 그래프에 제목 붙이기 plt.show()매트 플롯으로 이렇게 일일이 그래프를 그릴 수도 있지만
판다스 라이브러리는 매트 플롯을 통해 그래프 그리는 기능을 지원합니다.
막대 그래프 그려보기
xxxxxxxxxximport numpy as npimport pandas as pdimport randomimport matplotlib.pyplot as pltage = [random.randint(20, 100) for x in range(0, 50)] # 랜덤인 정수(정수 범위 0~100)가 50개 있는 리스트를 만듭니다. weight = [random.randint(40, 150) for i in range(0, 50)] df = pd.DataFrame({ 'age': age, 'weight': weight})df.plot(kind='bar', subplots=True) # pandas 라이브러리 써서 그래프 그림.plt.title('Bar Chart') # 차트에 제목 붙이기plt.savefig('bar_chart_random.png') # 차트 이미지로 저장하기plt.show() 4. 분석 예제 - 유제품 생산량 및 소비량 분석
이 데이터는 매년 생산되는 유제품(치즈, 버터, 연유, 탈지분유 등)의
생산량과 소비량을 나타내고 있습니다.
데이터의 항목은 년도(year), 유제품 종류(dairy), 생산량(production), 소비량(consumption) 으로 이뤄져 있습니다.
어떤 유제품이 더 많이 소비되는지를 보면 산업의 대략적인 흐름을 알 수 있겠죠?
4.1.1 유제품 전체 생산량, 소비량
xxxxxxxxxximport pandas as pddata = pd.read_csv('csv/milk.csv')# 위의 5개 데이터만 출력print(data.head(5)) # 열 이름 출력 - 'year', 'dairy', 'production', 'consumption'print(data.columns)data = data.set_index('year') # index를 year로 정합니다. index는 데이터를 구분할 때 쓰는 기준입니다. print(data.describe())print(data.min())print(data.max())데이터를 묶어서 보니 의미를 알기가 어렵죠.
평균이랑 최대값을 구했는데도 어디에 써야할지 모르겠네요.
데이터를 좀 더 세분화해서 볼께요.
4.2.1 유제품 종류로 본 생산량, 소비량
유제품 별로 나눠서 데이터를 보도록 하겠습니다.
groupby() 함수를 쓸께요.
데이터 타입은 숫자형(numerical data), 범주형(categorical data)가 있는데요.
숫자형은 1,2,3 같은 숫자로 되어 있는 데이터 타입을 말합니다. 판매량, 가격 같은 게 숫자형이지요.
범주형은 몇개의 종류로 나눠진 데이터 형태를 말합니다.
셩별(남자/여자), 혈액형(A/B/O/AB), 영화장르(코미디/액션/로맨틱/호러), 성적(1등/2등/3등/4등/5등)
groupby()는 범주형 데이터에 적용해 주는 게 좋습니다.
xxxxxxxxxximport pandas as pddata = pd.read_csv('csv/milk.csv')grouped_dairy = data.groupby('dairy')# 유제품들의 연평균 생산량과 소비량을 출력print(grouped_dairy.mean())# 유제품이 가장 적게 소비되고, 생산된 연도의 데이터를 출력print(grouped_dairy.min())# 유제품이 가장 많이 소비되고, 생산된 연도의 데이터를 출력print(grouped_dairy.max())# 특정 dairy의 값만 출력grouped_dairy.get_group('치즈')grouped_dairy.get_group('연유')grouped_dairy.get_group('연유').sort_values('year', ascending=True) # sort_values() - 정렬함. 오른차순으로.# group by로 정렬 후, 특정 year의 값만 출력grouped_year = data.groupby('year')grouped_year.get_group(2015) grouped_year.get_group(2011) 4.2.2 시각화 하기
유제품별 생산량과 소비량을 그래프로 그려보겠습니다.
그래프로 그리면 어떤 제품이 생산량 대비 소비가 많은지 알 수 있겠죠.
소비량이 생산량보다 많으면 수입을 하겠죠?
xxxxxxxxxxdef milk_graph(): import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv('csv/milk.csv') data = data.set_index('year') grouped_dairy = data.groupby('dairy') for key, group in grouped_dairy: group_sorted = group.sort_values('year', ascending=True) group_sorted.plot(kind='bar', subplots=False) plt.legend(['production', 'consumption']) plt.xlabel(key) plt.savefig('milk_graph_{}.png'.format(key)) plt.show() plt.close()milk_graph()5. 분석 예제 - 온라인 쇼핑몰 데이터 보기
온라인 쇼핑몰 데이터를 분석해볼께요.
공공 데이터 포털에서 구했구요. 아마도 네이버 스마트 스토어를 크롤링한 것 같아요.
제품의 id(good_id), 가격(sales_price), 제품 종류(pun_name) 등의 항목으로 구성되어 있습니다.
아래 코드를 보면서 어떤 데이터인지 알아볼께요.
xxxxxxxxxximport pandas as pdimport numpy as npdf = pd.read_csv('csv/commerce_20190301.csv')print(df[df['sales_price'] < 10000]) # 판매 가격이 10,000원 아래인 물품만 출력합니다. df_filtered = df[df['sales_price'] < 10000] df_sorted = df_filtered.sort_values('sales_price', ascending=False) # 판매가격이 10,000원 이하인 제품중에 싼 순으로 정렬합니다. print(df_sorted.head(5)) # head()는 위에서부터 데이터 프레임을 잘라서 쓸 때 씁니다. head(5)는 5개만 데이터를 쓴다는 뜻이죠.category = df.groupby('pum_name') # 항목별로 데이터를 묶습니다. # agg()는 데이터 프레임에 여러 함수를 적용할 때 씁니다. 최소값(min), 최대값(max), 평균(mean)을 한번에 구하고 있습니다. category_agg = category.agg([np.min, np.max, np.mean]) print( category_agg) print( category_agg.columns)print( category_agg[['sales_price', 'discount_price']] ) # sales_price와 discount_price 열만 확인합니다. 데이터의 형태를 알아보았으니
제품의 항목별로 나눠서 보도록 할께요.
xxxxxxxxxxdf = pd.read_csv('csv/commerce_20190301.csv')grouped_by_category = df.groupby('pum_name')running_suit = grouped_by_category.get_group('운동복') # 제품 종류 중에서 운동복만 가져다 쓰려고 합니다.print(running_suit)print(running_suit.min())print(running_suit.max())운동복의 최저가는 4350인데, 최고가는 389,920 이네요.
여러 날의 데이터를 수집한다면 제품 가격의 변화를 알아내거나, 물가 변동을 알 수 있겠죠.
하루치 데이터라 분석이 좀 단순하긴 한데요.
크롤링과 합치면 분석을 응용할 곳이 많습니다.
해외에서 수입해서 중간 거래만 하는 사람이라면, 경쟁 상대가 상품을 얼마에 올리는가,
해외에선 동일한 제품이 얼마인가를 자동화 툴로 주시하다가
이익이 날만한 제품만 올릴 수도 있죠.
특히 1일치 데이터 뿐만 아니라 장기간 데이터를 수집하면 가치가 더 올라갑니다.
경쟁상대는 몇명이 있는가, 가격이 올라가는 추세인가, 떨어지는 추세인가 알아볼 수 있죠.
다만 온라인 쇼핑 데이터 수집할 때는 단위(3kg, 50개)를 보고, 그 단위에 맞게 가격등을 조절해야합니다.
이 글에서는 하지 않았지만 직접 해보시기를 권합니다.
이번 글과 지난 글에서 정말 기본적인 크롤링과 분석 라이브러리 사용법을 알아보았습니다.
다음에는 크론잡으로 주기적으로 크롤링 하는 법을 알아보겠습니다.
참고 사이트 - numpy 라이브러리 설명, 스탠포드 수업 ( http://cs231n.github.io/python-numpy-tutorial/ )
참고 사이트 - 공공 데이터 포펄 ( https://www.data.go.kr/search/index.do )
추천 영상 - 인생은 짧아요. 엑셀 대신 파이썬 (https://www.youtube.com/watch?v=w7Q_eKN5r-I&list=PLp5Djnc0GE9FVYIi2WXNatf9AmZ0TWVOO&index=2&t=0s)
용어 정리 - 공분산과 상관계수 ( https://datascienceschool.net/view-notebook/4cab41c0d9cd4eafaff8a45f590592c5/ )
이미지 출처 - The components of a DataFrame (https://medium.com/epfl-extension-school/selecting-data-from-a-pandas-dataframe-53917dc39953 )
'파이썬' 카테고리의 다른 글
| 파이썬 정규표현식 배워보기 (4) | 2021.01.09 |
|---|---|
| 파이썬 크롤링 시작하기 - html 구조와 간단한 크롤링 (5) | 2019.04.17 |
| 파이썬 기초 문법 정리 (3) | 2019.04.11 |